


이길어때 프로젝트의 장소 상세 화면에서는 리뷰 개수, 댓글 수, 좋아요 수, 평균 평점 등 여러 집계 정보가 필요합니다. 그런데 이 값들을 계산할 때마다 여러 개의 COUNT 쿼리가 실행되면서 DB 부담이 점점 커지는 문제가 생겼습니다.
이 글에서는 이 문제를 Redis 캐싱으로 어떻게 해결했는지, 그리고 마지막에 Spring Cache 추상화(@Cacheable)를 적용해 비즈니스 로직을 깔끔하게 정리한 과정을 소개합니다.
이 글을 읽으면 다음 내용을 알 수 있을거에요
- Count 기반 데이터를 언제 캐싱하면 좋은지
- Spring + Redis로 Cache-Aside 패턴을 구현하는 방법
- Spring Cache 추상화를 활용해 캐시 로직을 서비스 코드에서 분리하는 실전 패턴
문제 상황: 장소 상세 화면에 반복되는 Count 쿼리

서비스 시나리오
이길어때 서비스에서 사용자는 게시글을 작성하고, 좋아요와 댓글로 상호작용할 수 있습니다. 각 게시글은 하나의 좌표를 가지며, 같은 좌표를 공유하는 게시글들이 모여 하나의 장소(Place)를 이룹니다.
사용자가 장소 상세 화면을 열면 이 장소와 관련된 여러 집계 정보가 한 번에 필요합니다.
한 화면에서 조회되는 수 많은 정보들
- 장소 안의 리뷰(게시글) 개수
- 리뷰별 댓글 수
- 리뷰별 좋아요 수
- 장소의 평균 평점
단순한 숫자처럼 보이지만, 실제로는 각각 별도의 COUNT 쿼리를 실행해야 합니다.
Count 쿼리의 병목
COUNT 쿼리는 “단순히 개수를 세는 쿼리”처럼 보이지만, 내부적으로는 많은 행을 스캔해야 합니다.
데이터가 늘어날수록 쿼리 실행 시간이 빠르게 증가하고, 장소 상세 화면은 페이지 이동마다 새로 호출되기 때문에 DB 부하가 누적되기 시작했습니다.
DB 튜닝만으로 해결이 어려운 이유
시도했던 DB 레벨의 최적화
- COUNT(*) → COUNT(id)로 전환하고 인덱스를 적용
- 테이블 파티셔닝 또는 분할 검토
여러 최적화를 시도했지만, 화면 조회마다 반복되는 대량의 Count 요청을 처리하기에는 근본적인 한계가 있었습니다.
Redis 캐싱을 고려한 이유
- 동일한 Count 값을 화면을 열 때마다 다시 계산하는 것은 불필요한 비용입니다.
- 대부분의 Count 값은 실시간 정합성이 아주 중요하지 않습니다.
- 조회가 압도적으로 많고 실시간 변경은 중요성이 떨어지거나, 상대적으로 적은 구조입니다.
이런 특성은 Redis 캐싱과 잘 맞았습니다.
결국 자주 조회되는 집계 값만 캐싱해 DB 부담을 줄이자는 방향으로 결정했습니다.
Redis + Cache-Aside 패턴 적용
캐싱 대상 선정 기준
- 실시간 정확도보다 빠른 조회가 더 중요한 값
- 계산 비용이 높은 집계·COUNT 기반 데이터
- 요청 빈도가 높은 값
이 기준에 따라, 먼저 장소의 게시글 개수(postCount)를 캐싱 대상으로 선정했습니다.
Cache-Aside 패턴
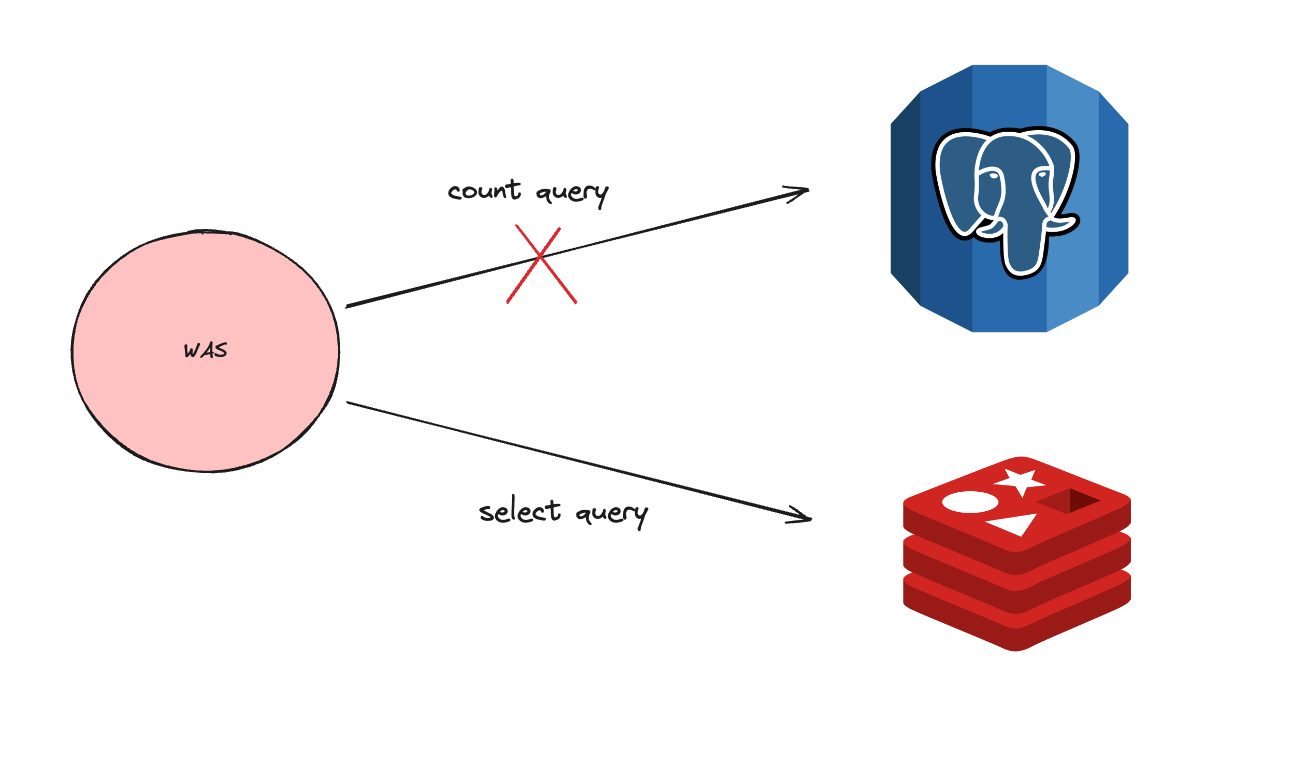
Cache-Aside 패턴은 다음 순서로 동작합니다.
- 먼저 Redis에서 값을 조회한다.
- 값이 있으면 그대로 반환한다. (캐시 히트)
- 값이 없으면 DB에서 조회한다.
- 조회한 결과를 Redis에 저장하고 반환한다. (캐시 미스 처리)
이 흐름을 기반으로 첫 번째 캐싱 구현을 진행했습니다.
Spring Data Redis로 PostCount 직접 캐싱
의존성과 기본 설정
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
}spring:
data:
redis:
host: localhost
port: 6379@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
}
Redis 엔티티(PostCount) 정의
@Getter
@AllArgsConstructor
@RedisHash("postCount")
public class PostCount {
@Id
private Long placeId;
private int postCount;
public void incrementPostCount() {
postCount++;
}
public void decrementPostCount() {
postCount--;
}
}
Repository 구성
public interface PostCountRepository extends CrudRepository<PostCount, Long> {
Optional<PostCount> findByPlaceId(Long placeId);
}
Cache-Aside 패턴 직접 구현
@Service
@RequiredArgsConstructor
public class PostRedisIntegrityService {
private final PostRepository postRepository;
private final PostCountRepository postCountRepository;
@Transactional
public PostCount ensurePostCount(Long placeId) {
return postCountRepository.findByPlaceId(placeId)
.orElseGet(() -> {
PostCount postCount = new PostCount(
placeId,
postRepository.countByPlaceId(placeId)
);
return postCountRepository.save(postCount);
});
}
}
이 방식의 단점

초기 구현은 동작은 하지만 여러 아쉬움이 있었습니다.
- 캐싱 로직이 서비스 메서드 곳곳에 섞여 코드가 복잡해짐
- orElseGet, 캐시 미스 처리 등 반복되는 패턴이 계속 등장
- 비즈니스 로직의 의도가 흐려지고 가독성이 떨어짐
- 캐싱 정책이 바뀌면 수정해야 할 코드가 많아 유지보수가 어려움
이런 이유로 캐싱은 캐싱대로 분리하고, 서비스는 비즈니스 로직만 담당하게 하자는 방향을 고민했고, 그 해결책으로 스프링의 캐시 추상화(@Cacheable)를 도입하게 되었습니다.
Spring Cache 추상화(@Cacheable)로 단순화
CacheManager 설정 및 캐싱 기능 활성화
@Configuration
@EnableRedisRepositories
@EnableCaching
public class RedisConfig {
@Bean
public CacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(60L));
return RedisCacheManager.builder(cf)
.cacheDefaults(config)
.build();
}
}
@Cacheable로 캐싱 적용
@Service
@RequiredArgsConstructor
public class PlaceService {
private final PostRepository postRepository;
@Cacheable(value = "postCount", key = "#placeId")
public int getPostCount(Long placeId) {
return postRepository.getPostCountInPlace(placeId);
}
}@Cacheable만 붙여도 캐시 조회 → 캐시 미스 시 DB 조회 → 캐시 저장 과정을 자동으로 처리합니다.
이제 서비스 메서드는 게시글 수를 조회한다는 본래의 역할만 담으면 됩니다.
이 방식의 장점
- 캐싱 로직이 메서드 밖으로 완전히 분리됨
- 비즈니스 로직이 깔끔해지고 의도가 명확해짐
- 캐시 TTL, 저장 방식 등 정책을 중앙에서 일괄 관리 가능
- 여러 서비스에서 동일한 메서드를 호출해도 일관된 캐싱 규칙이 적용됨
결과적으로 전체 코드 구조가 단순해지고 유지보수성이 크게 향상되었습니다.
운영 시 고려해야 할 포인트
TTL 설정 전략
TTL이 너무 길면 오래된 값이 유지되어 stale 데이터가 발생할 수 있고,
반대로 너무 짧으면 캐시 적중률이 떨어져 DB 부하가 다시 증가합니다.
서비스 특성에 맞춰 적절한 TTL을 설정하는 것이 중요합니다.
쓰기 이벤트 처리
게시글이 생성되거나 삭제되면 캐시 값도 함께 갱신해야 합니다.
이때 @CacheEvict 또는 @CachePut을 활용해 캐시를 무효화하거나 갱신하는 방식을 고려할 수 있습니다.
캐시 장애 시 fallback 전략
Redis가 장애를 일으켜도 서비스 전체가 영향을 받지 않도록 설계해야 합니다.
캐시에 접근할 수 없는 상황에서는 DB 조회로 자연스럽게 fallback하도록 구성하면 안정성을 높일 수 있습니다.
장소 상세 화면에서 발생하던 수많은 Count 쿼리는 서비스가 성장할수록 큰 병목으로 이어질 수 있었습니다.
처음에는 Spring Data Redis로 캐시 엔티티를 직접 관리했지만, 결국 스프링의 캐시 추상화를 도입하면서 더 깔끔하고 확장 가능한 구조를 만들 수 있었습니다.
이번 경험을 통해 집계성·반복성이 높은 데이터는 캐시를 적용했을 때 비용 대비 효과가 크다는 점을 다시 한 번 확인했습니다.
앞으로는 여러 Count 값을 하나의 DTO로 묶어 캐싱하거나, 쓰기 이벤트 기반 캐시 갱신 패턴도 점진적으로 적용해볼 계획입니다.
'Backend > Spring 🌱' 카테고리의 다른 글
| Spring Boot에서 PostgreSQL Master–Slave Replication 적용하기 (0) | 2025.11.27 |
|---|---|
| Spring에서 ServiceImpl, 정말 써야 할까요? (0) | 2024.06.14 |
| Spring SSE와 Redis Pub/Sub으로 구현하는 실시간 알림 (다중 서버 환경까지 스케일링하기) (0) | 2024.03.19 |
| 스프링 컨테이너 이해하기: BeanFactory와 ApplicationContext (0) | 2024.03.12 |
| Spring MVC에서 HandlerMapping과 HandlerAdapter를 나눈 이유 (0) | 2024.02.07 |
안녕하세요, 저는 주니어 개발자 박석희 입니다. 언제든 하단 연락처로 연락주세요 😆



