


GC(Garbage Collection)를 처음 접하면 흔히 '사용하지 않는 메모리를 자동으로 지워 주는 기능'이라고 생각하기 쉬워요.
틀린 말은 아니지만, 이 설명만으로는 GC의 진짜 핵심을 놓칠 수 있습니다.
GC의 진정한 출발점은 메모리를 비우는 동작 자체가 아니라, 무엇을 회수 대상으로 볼 것인지 판단하는 일에 있기 때문이죠.
메모리에서 어떤 객체를 회수하려면 먼저 그 객체가 더 이상 쓰이지 않는다고 판정해야 해요.
즉, GC를 제대로 이해하려면 가장 먼저 죽은 객체란 무엇인가?를 정의해야 합니다.
이 판정 기준이 명확히 서야 비로소 실제 수거 알고리즘이 의미를 가지거든요.
이번 글에서는 객체의 생사 판정 기준을 시작으로, JVM의 메모리 관리 전략을 단계별로 알아볼게요.
💡 이 글에서 다룰 내용
- 객체의 생존을 판단하는 두 가지 방식 (참조 카운팅 vs 도달 가능성 분석)
- 도달 가능성 분석의 출발점, GC Roots의 개념
- 생사 판정 이후 실제 메모리를 회수하는 알고리즘의 큰 그림
- JVM이 메모리를 세대(Generation) 단위로 나누어 효율적으로 관리하는 이유
GC의 첫 단계는 회수가 아닌 생존 판정
보통 GC를 공부할 때 마크-스윕(Mark-Sweep)이나 마크-컴팩트(Mark-Compact) 같은 수거 알고리즘부터 접하기 쉬워요.
실제로 저도 이전에 간단히 JVM-GC에 대한 학습을 하고 블로그에 남긴 글도 그랬어요.
하지만 그보다 먼저 던져야 할 질문이 있습니다.
바로 이 객체가 살아 있는가, 아니면 죽었는가? 예요.
GC는 무작정 메모리를 비우지 않아요.
프로그램 실행에 더 이상 필요하지 않은 객체를 먼저 찾아냅니다.
즉, 생존 판정과 메모리 회수는 완전히 다른 단계예요.
- 생존 판정: 이 객체가 앞으로도 참조될 수 있는가?
- 메모리 회수: 죽은 객체의 메모리를 어떤 방식으로 정리할 것인가?
이 두 가지를 분리해서 생각하면 GC의 전체 구조가 훨씬 명확해집니다.
예를 들어, JVM이 '도달 가능성 분석'으로 객체의 생존 여부를 판정하더라도, 실제 메모리를 정리하는 방식은 마크-스윕일 수도 있고 마크-컴팩트일 수도 있어요.
판정 기준과 회수 방식은 서로 독립적인 과정이니까요.
GC는 먼저 누가 죽었는가(생존 판정)를 결정하고, 그 다음에 어떻게 치울 것인가(메모리 회수)를 결정합니다.
가장 직관적인 방식, 참조 카운팅

객체의 생존 여부를 판단하는 가장 직관적인 방법은 참조 카운팅(Reference Counting)이에요.
이름 그대로 어떤 객체를 가리키는 참조(Reference)의 개수를 세는 방식입니다.
객체 A를 참조하는 변수가 하나 생기면 카운트를 1 올리고, 참조가 사라지면 1 내립니다.
카운트가 0이 되면 더 이상 이 객체를 가리키는 곳이 없다고 판단해 메모리를 회수하죠.
누가 이 객체를 보고 있는가?를 숫자로 명확하게 관리하니 이해하기도 쉽고 구현도 단순하다는 장점이 있어요.
하지만 이 방식에는 순환 참조(Circular Reference)라는 치명적인 한계가 있습니다.
예를 들어, 객체 A와 객체 B가 서로를 참조하고 있다고 가정해 볼게요.
그런데 이 두 객체를 가리키던 외부의 참조는 모두 사라졌습니다.
프로그램 입장에서는 더 이상 A와 B에 접근할 수 없으니 명백히 '죽은 객체'예요.
하지만 두 객체가 서로를 참조하고 있어서 각자의 참조 카운트는 영원히 0이 되지 않습니다.
결과적으로 실제로는 죽은 객체인데도 메모리에 계속 살아남게 되죠.
즉, 참조 카운팅은 참조가 존재하는가?는 잘 알아내지만, 실제로 프로그램 실행의 시작점에서 도달 가능한가?는 판별하지 못해요.
바로 이 한계 때문에 현대 JVM은 단순히 참조 수를 세는 대신, 실제로 도달 가능한 객체인지를 기준으로 생존을 판단합니다.
여기서 등장하는 개념이 바로 도달 가능성 분석(Reachability Analysis)이에요.
현대 JVM의 기준, 도달 가능성 분석(Reachability Analysis)
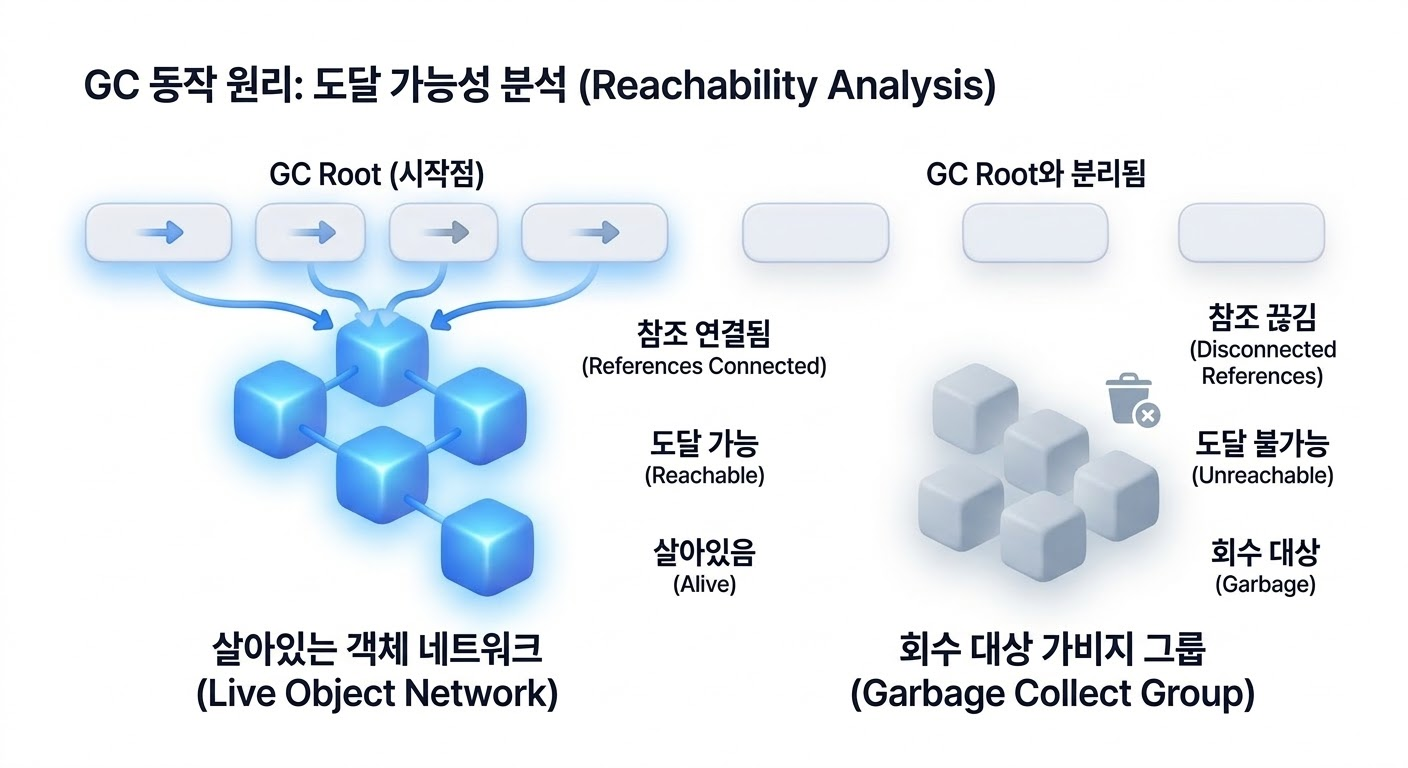
현대 JVM은 객체의 생존 여부를 판정할 때 참조 횟수를 세지 않아요.
대신 도달 가능성 분석(Reachability Analysis)을 사용합니다.
특정한 시작점(Root)들로부터 이 객체에 실제로 닿을 수 있는지(Reachable)를 따지는 방식이죠.
프로그램이 실행 중일 때는 반드시 '현재 유효한 참조의 출발점'이 존재합니다.
이를 GC Roots라고 부르며, 주로 다음과 같은 항목들이 포함돼요.
- 실행 중인 메서드의 지역 변수 (Local Variables)
- 정적 필드 (Static Fields)
- 네이티브 코드(JNI)가 붙잡고 있는 참조
도달 가능성 분석은 이 GC Roots에서 시작해 객체들의 참조 그래프를 따라 탐색을 진행해요.
이 탐색 경로를 통해 도달할 수 있는 객체는 살아있는 것으로 판정하고, 어떤 경로로도 닿지 않는 객체는 더 이상 사용할 수 없는 상태(Unreachable)로 간주해 회수합니다.
이 방식의 가장 큰 장점은 앞서 살펴본 순환 참조 문제를 완벽하게 해결한다는 거예요.
객체 A와 B가 서로를 가리키고 있더라도, GC Roots에서 출발한 탐색 경로가 A나 B에 닿지 않는다면 둘 다 죽은 객체로 판정됩니다.
서로 연결되어 있다는 사실 자체는 생존을 보장해 주지 않아요.
중요한 건 'GC Roots에서 닿을 수 있는가'입니다.
도달 가능성 분석은 참조 카운팅보다 실제 런타임의 의미에 훨씬 가깝습니다.
프로그램이 어떤 객체를 사용할 수 있으려면, 결국 현재 실행 상태(GC Roots)에서 그 객체에 접근할 수 있어야 하니까요.
참조 카운팅이 숫자에 집중한다면, 도달 가능성 분석은 실질적인 연결성을 봅니다.
바로 이 연결성이 현대 JVM이 객체의 생존을 판단하는 핵심 기준이에요.
GC Roots는 어디에서 시작될까요?

도달 가능성 분석이 정확히 어디서부터 출발하는지, 즉 GC Roots의 실체를 알아볼 차례예요.
JVM은 객체의 생존을 판단할 때 임의의 위치에서 탐색을 시작하지 않습니다.
'현재 프로그램이 확실하게 쥐고 있는 참조'들만을 출발점으로 삼죠.
대표적인 GC Roots는 크게 세 가지로 나눌 수 있어요.
- 스택 프레임의 지역 변수 (Local Variables): 현재 실행 중인 메서드 내의 지역 변수가 참조하는 객체예요. 실행 흐름에서 직접 사용 중인 값이므로, 가장 기본적이고 확실한 생존 판정의 출발점입니다.
- 클래스의 정적 참조 (Static Fields): 메서드 영역(Method Area)에 로드된 클래스의
static필드가 가리키는 객체예요. 특정 인스턴스에 종속되지 않으므로 개별 메서드 호출이 끝나도 참조가 계속 유지됩니다. - JNI (Java Native Interface) 참조: JVM 바깥의 네이티브 코드가 붙잡고 있는 자바 객체예요. 자바 코드 내에서는 닿지 않는 것처럼 보여도 네이티브 환경에서 사용 중일 수 있으므로 반드시 GC Roots에 포함해야 해요
이 밖에도 실행 중인 스레드나 JVM 내부 구조가 유지하는 참조들이 포함될 수 있어요.
여기서 가장 중요한 핵심은 GC Roots가 '현재 실행 상태에서 유효성이 보장된 참조들의 집합'이라는 사실이에요.
언제나 이 루트 집합에서 닿을 수 있는가?가 생존의 절대적인 기준이 되죠.
이 관점을 확실히 잡아두면, 나중에 HotSpot JVM의 런타임 데이터 영역(스택, 메서드 영역 등)을 공부할 때 GC의 동작 원리를 훨씬 입체적으로 해석할 수 있답니다.
죽었다고 판정된 객체는 어떻게 회수할까요?
생존 판정이 끝났다면, 이제 JVM은 회수 대상으로 분류된 객체들의 메모리를 정리해야 해요.
앞서 강조했듯 생존 판정과 메모리 회수는 완전히 다른 단계의 문제입니다.
죽은 객체를 치우는 대표적인 알고리즘으로는 마크-스윕(Mark-Sweep), 마크-카피(Mark-Copy), 마크-컴팩트(Mark-Compact) 세 가지가 있어요.
이들은 모두 생존 판정(Mark)'결과를 바탕으로 동작한다는 공통점이 있지만, 메모리를 정리하는 방식에 따라 명확한 트레이드오프(Trade-off)를 가집니다.
- 단순하지만 단편화(Fragmentation)가 남는 방식 (마크-스윕)
- 단편화를 줄이는 대신 객체를 이동시키는 비용이 드는 방식 (마크-컴팩트)
- 빠르고 깔끔하지만 메모리 추가 공간이 필요한 방식 (마크-카피)
마크-스윕 (Mark-Sweep)

가장 기본이 되는 회수 방식이에요.
먼저 GC Roots에서 도달 가능한 살아있는 객체를 표시(Mark)하고, 표시되지 않은 죽은 객체의 메모리만 쓸어내듯 회수(Sweep)합니다.
구조가 단순하지만, 메모리 곳곳에 빈 공간이 흩어지는 단편화(Fragmentation)가 발생하기 쉽다는 치명적인 단점이 있어요.
단편화가 심해지면 전체 여유 메모리는 넉넉해도 덩치가 큰 객체를 새로 할당하지 못하는 상황이 생길 수 있습니다.
마크-카피 (Mark-Copy)

메모리를 두 구역으로 나누고, 살아있는 객체만 새로운 구역으로 복사(Copy)한 뒤 기존 구역을 통째로 비워버리는 방식이에요.
죽은 객체를 일일이 지울 필요가 없어 처리 속도가 빠르고 단편화도 전혀 발생하지 않죠.
특히 살아남는 객체의 비율이 낮은 상황에서 매우 효율적입니다.
하지만 항상 객체를 복사해 둘 별도의 여유 공간(절반의 메모리)이 필요하다는 것이 단점이에요.
공간 효율을 일부 포기하고 정리 효율을 극대화한 방식입니다.
마크-컴팩트 (Mark-Compact)

살아있는 객체들을 메모리의 한쪽 끝으로 촘촘하게 밀어 넣어 압축(Compact)하는 방식이에요.
마크-스윕의 단점인 단편화를 해결하면서도, 마크-카피처럼 큰 빈 공간을 항상 유지할 필요가 없어요.
하지만 살아있는 객체들을 실제로 이동시켜야 하고, 그에 따라 객체를 가리키던 모든 참조(메모리 주소)를 업데이트해야 하므로 객체 이동 비용(Overhead)이 꽤 큽니다.
정리하자면 세 알고리즘은 모두 '생존 판정' 결과를 바탕으로 동작하지만, 메모리 단편화, 추가 공간 확보, 객체 이동 비용이라는 뚜렷한 트레이드오프를 가지고 있어요.
JVM은 메모리 영역의 특성과 객체의 생존 패턴에 맞춰 이 알고리즘들을 적절히 섞어 사용하게 됩니다.
왜 힙 메모리를 세대(Generation)별로 나누어 관리할까요?

JVM은 힙(Heap) 전체를 하나의 덩어리로 보지 않고, 객체의 생존 기간(생애 패턴)에 따라 세대(Generation) 단위로 나누어 관리해요.
모든 객체를 똑같이 취급해서 매번 전체 메모리를 검사하면 너무 비효율적이기 때문이죠.
이 설계의 바탕에는 개발자들이 오랜 경험을 통해 증명해 낸 중요한 가설이 있습니다.
- 약한 세대 가설 (Weak Generational Hypothesis): 대부분의 객체는 생성된 직후 아주 빨리 죽는다. (예: 메서드 호출 시 잠깐 쓰이는 임시 객체)
- 강한 세대 가설 (Strong Generational Hypothesis): 오래 살아남은 객체는 앞으로도 계속 살아남을 가능성이 높다. (예: 애플리케이션 수명과 함께하는 전역 객체)
이 가설에 따라 JVM은 메모리를 크게 두 영역으로 나누어 각기 다른 GC 알고리즘을 적용합니다.
- Young 영역 (Young Generation): 방금 생성된 객체들이 모이는 곳이에요. 대부분 금방 죽기 때문에, 살아남은 소수의 객체만 빠르게 옮기는 마크-카피(Mark-Copy) 방식이 매우 효율적입니다.
- Old 영역 (Old Generation): Young 영역에서 여러 번의 GC를 견디고 살아남은 객체들이 이동하는 곳이에요. 여기 객체들은 잘 죽지 않으므로, 단편화를 방지하고 공간을 꽉 채워 쓰는 마크-컴팩트(Mark-Compact) 등의 방식이 훨씬 적합하죠.
즉, 세대별 메모리 분리는 단순히 구역을 나누는 것을 넘어, 앞서 배운 다양한 회수 알고리즘들을 각 메모리 특성에 맞게 적재적소에 배치하는 핵심 논리가 됩니다.
엄연히 다른 힙 객체 회수와 클래스 언로딩(Class Unloading)
GC를 이야기할 때 흔히 "메모리를 회수한다"라고 뭉뚱그려 표현하기 쉽지만, 내부를 들여다보면 성격이 완전히 다른 작업이 섞여 있어요. 특히 힙(Heap) 객체 회수와 클래스 언로딩(Class Unloading)을 같은 선상에서 이해하면 안 됩니다.
- 힙 객체 회수: 힙 영역에 할당된 인스턴스(객체)가 더 이상 도달 불가능(Unreachable)해졌을 때 해당 메모리를 비우는 작업이에요.
- 클래스 언로딩: 메서드 영역(Metaspace 등)에 로드된 타입 정보, 클래스 메타데이터, 상수 풀 등이 더 이상 필요 없을 때 정리하는 작업이에요.
이 둘은 난이도와 발생 조건부터가 다릅니다.
일반적인 객체 하나를 지우는 것보다, 클래스 자체를 메모리에서 내리는 판정이 훨씬 까다로워요.
클래스 언로딩이 일어나려면 해당 클래스의 인스턴스가 힙에 하나도 없어야 하고, 클래스 로더의 상태나 정적 참조 유지 여부 등 훨씬 복잡한 조건을 모두 통과해야 하거든요.
그래서 실무에서 "GC가 일어났다"는 말과 "클래스가 언로드되었다"는 말을 섞어서 쓰면 오해가 생기기 쉽습니다.
보통 GC라고 하면 전자인 힙 객체 회수를 가리키는 경우가 많으니까요.
나중에 HotSpot JVM의 런타임 데이터 영역과 메타데이터 영역을 더 깊게 파고들수록, 이 두 가지를 명확히 구분하는 것이 디버깅의 핵심이 될 거예요.
어떻게 치울 것인가보다 중요한 건, 무엇을 지울 것인가
GC를 공부할 때 가장 먼저 붙잡아야 할 핵심은 어떻게 치우는가보다 무엇을 죽은 객체로 보는가예요.
GC는 단순히 알아서 메모리를 비워주는 마법 상자가 아닙니다.
객체의 생존 여부를 먼저 판정하고, 그 결과를 바탕으로 회수를 수행하는 아주 체계적인 시스템이죠.
오늘 다룬 전체적인 흐름을 세 줄로 요약해 볼까요?
- 생사 판정이 먼저, 회수 알고리즘은 그다음: 객체의 생존 여부를 먼저 가려내야 비로소 마크-스윕, 마크-카피, 마크-컴팩트 같은 회수 알고리즘이 제 역할을 할 수 있어요.
- 현대 JVM의 생사 판정 기준은 연결성: 순환 참조 문제를 안고 있는 참조 카운팅 대신, GC Roots에서 출발해 도달 가능성(Reachability)을 탐색하는 방식이 핵심이에요.
- 생애 주기에 맞춘 세대별 관리: 대부분의 객체가 일찍 죽는다는 가설에 따라, 힙 메모리를 Young과 Old 영역으로 나누어 각기 다른 최적의 회수 전략을 적용합니다.
이번 글을 통해 GC가 무작정 메모리를 훑는 것이 아니라, "누가 살아남아야 하는가?"를 치열하게 묻고 찾아내는 과정이라는 점을 느끼셨기를 바라요.
다음 포스팅에서는 이 생사 판정 이론이 HotSpot JVM의 실제 구조와 어떻게 연결되는지 알아볼 예정입니다.
런타임 데이터 영역(Runtime Data Area)과 GC Roots가 실제 구현 관점에서 어떻게 맞물려 돌아가는지, 한 단계 더 깊은 이야기로 돌아올게요!
'Language > Java ☕️' 카테고리의 다른 글
| JVM 메모리 장애 분석: OutOfMemoryError와 StackOverflowError를 제대로 이해하기 (0) | 2026.03.09 |
|---|---|
| 자바 객체는 메모리에 어떻게 배치될까요? 객체 생성 과정과 메모리 레이아웃 (0) | 2026.03.09 |
| 자바 메모리 구조: 힙만으로는 부족한 JVM 런타임 데이터 영역 이해하기 (0) | 2026.03.09 |
| Java static 키워드 완전 가이드 (0) | 2024.05.22 |
| 자바 메모리 구조 이해하기 (0) | 2024.05.22 |
안녕하세요, 저는 주니어 개발자 박석희 입니다. 언제든 하단 연락처로 연락주세요 😆



