![[MySQL] CHAR, VARCHAR, TEXT: 내 서비스에 딱 맞는 문자열 데이터 타입 선택하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FsCdAr%2FdJMcaa5tvSZ%2FAAAAAAAAAAAAAAAAAAAAAJ48nUToY6G86ZvG02NMnVliEytQzub63-XKMHAuraRy%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DnUf%252BhMa%252FvwISP3275QojuWbhFtQ%253D)


개발하며 가장 많이 다루는 데이터는 단연 문자열이죠.
백엔드 개발자라면 '이 문자열 데이터를 어떻게 효율적으로 저장하고 빠르게 불러올까?'를 늘 고민하게 돼요.
특히 데이터베이스 테이블을 설계할 때 CHAR와 VARCHAR 중 무엇을 쓸지 결정하는 건 흔히 겪는 난관이에요.
그래서 오늘은 MySQL의 대표적인 문자열 타입인 CHAR, VARCHAR, TEXT의 내부 동작 방식을 깊이 있게 살펴볼게요.
단순한 데이터 길이를 넘어, 디스크 공간 효율성과 업데이트 시 발생하는 성능 오버헤드까지 함께 짚어보겠습니다.
나아가 무중단 스키마 변경(Online DDL) 이슈까지 종합적으로 파악해 두면, 내 서비스에 딱 맞는 데이터 타입을 직접 결정하실 수 있을 거예요.
디스크 공간 할당 방식: 고정 길이 vs 가변 길이
CHAR와 VARCHAR는 모두 문자열을 저장하는 타입으로, ASCII나 UTF-8 같은 다양한 인코딩을 지원해요.
둘의 가장 큰 차이는 바로 '디스크 공간을 할당하는 방식'에 있어요.
CHAR(고정 길이): 선언한 길이만큼의 공간을 고정적으로 확보해요. 예를 들어CHAR(10)컬럼에 'abc'(3글자)를 저장하면, 남는 공간을 공백(Padding)으로 채워 10글자 크기의 디스크 공간을 온전히 차지하죠.
VARCHAR(가변 길이): 실제 들어온 데이터 길이에 맞춰 유연하게 공간을 써요. 똑같이 'abc'를 저장해도 딱 3글자 크기만 차지하니 디스크 공간 효율이 훨씬 뛰어나죠. 다만, 데이터가 얼만큼의 길이를 가졌는지 기록하기 위해 1~2바이트의 길이 정보 오버헤드가 추가로 발생해요. (데이터가 255바이트 이하면 1바이트, 그 이상이면 2바이트를 사용해요.)
이렇게 공간 효율만 놓고 보면 "길이가 일정하면 CHAR, 가변적이면 VARCHAR"라는 공식이 딱 맞아떨어지는 것 같아요. 하지만 실제 데이터베이스 운영 환경에서는 데이터가 '변경(Update)'될 때 일어나는 현상도 반드시 고려해야 한답니다.
데이터 업데이트가 빈번할 때의 함정: 로우 마이그레이션
VARCHAR는 딱 맞는 공간만 할당하기 때문에, 기존보다 더 긴 문자열로 수정(UPDATE)될 때 치명적인 성능 저하를 일으킬 수 있어요.
카카오톡 채팅 메시지를 VARCHAR로 저장하는 상황을 생각해 볼까요?

- 초기 저장: "안녕"이라는 데이터를 저장하면, 디스크에는 딱 그 길이에 맞는 공간만 할당돼요.
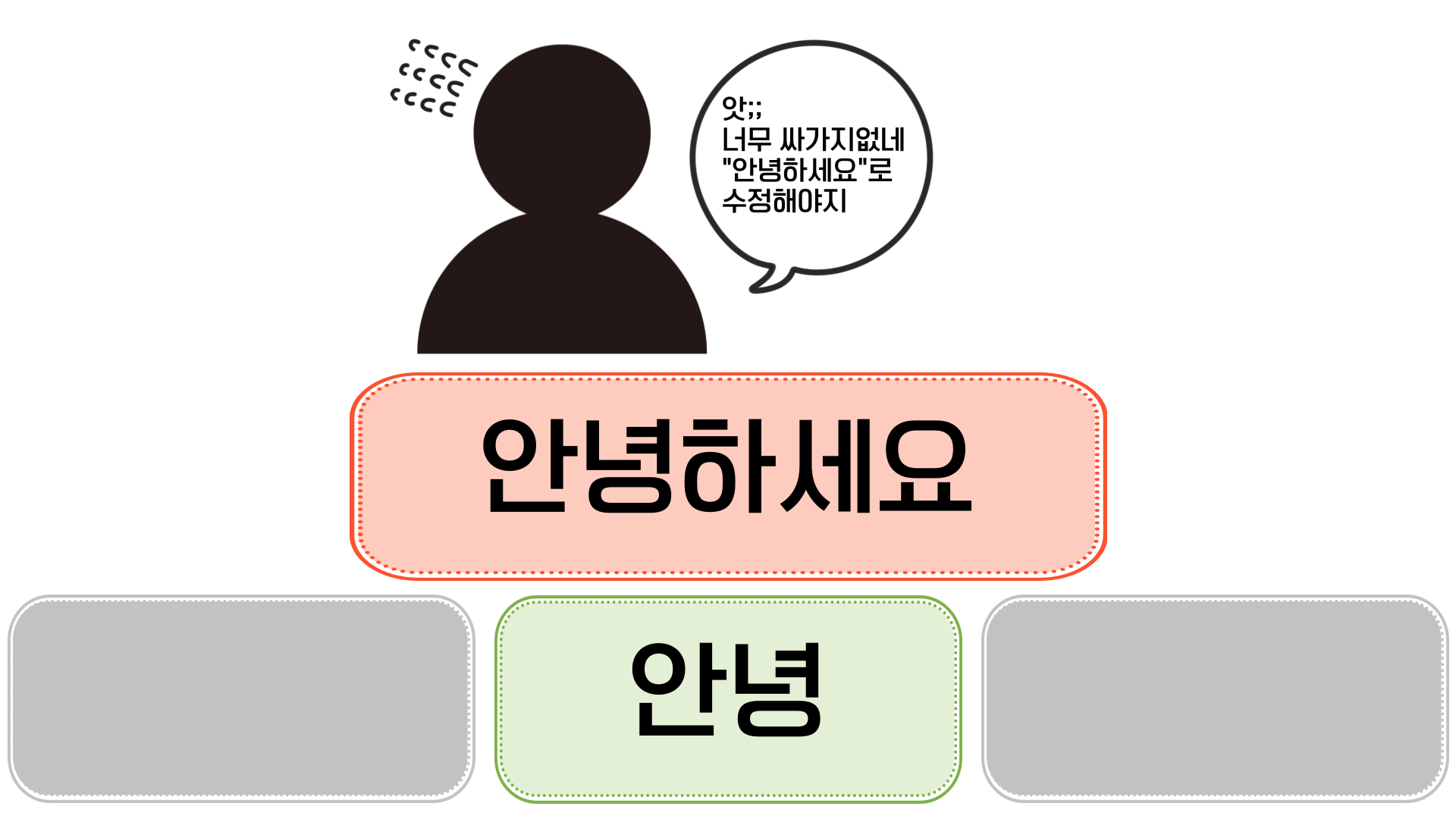
- 데이터 수정: 메시지가 너무 무뚝뚝한 것 같아 "안녕하세요"로
UPDATE를 시도해요. - 공간 부족 현상: 기존에 할당된 공간은 "안녕" 크기뿐이라, 더 길어진 "안녕하세요"를 덮어쓸 여유 공간이 부족해지죠.
이때 MySQL은 기존 레코드의 위치를 포기하고, 새로운 데이터를 통째로 저장할 수 있는 넉넉한 여유 공간을 찾아 레코드 전체를 다른 곳으로 이동시켜요. 이를 로우 마이그레이션(Row Migration)이라고 부릅니다.
이 과정에서 레코드를 옮기기 위한 추가적인 디스크 I/O가 발생해 상당한 성능 비용을 치르게 돼요.
따라서 상태 코드나 짧은 식별자처럼 데이터 길이 변화가 잦고 업데이트가 빈번한 컬럼이라면, 차라리 넉넉한 고정 공간을 미리 확보해 두는 CHAR 타입이 성능상 훨씬 유리하답니다.
운영 중 스키마 변경(Online DDL) 시 주의할 점
MySQL은 서비스 중단 없이 테이블 구조를 변경할 수 있는 Online DDL 기능을 지원해요.
하지만 VARCHAR의 길이를 늘릴 때는 내부 저장 방식 때문에 이 기능에 제약을 받을 수 있답니다.
예를 들어, utf8mb4 문자셋(1글자당 최대 4바이트 사용) 환경에서 VARCHAR(10)을 VARCHAR(60)으로 늘린다고 가정해 볼게요.
ALTER TABLE test
MODIFY value VARCHAR(60),
ALGORITHM = INPLACE,
LOCK = NONE;
-- Query OK, 0 rows affected
VARCHAR(60)은 최대 240바이트(60 * 4)를 사용해요.
여전히 255바이트 이하이므로 데이터 길이를 기록하는 메타데이터가 1바이트면 충분하죠.
따라서 테이블 복사 없이 INPLACE 알고리즘을 통해, 락(Lock)을 걸지 않고 즉시 스키마를 변경할 수 있어요.
하지만 길이를 조금 더 늘려 VARCHAR(64)로 변경하면 결과가 완전히 달라져요.
ALTER TABLE test
MODIFY value VARCHAR(64),
ALGORITHM = INPLACE,
LOCK = NONE;
-- ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported.
VARCHAR(64)는 최대 256바이트(64 * 4)를 요구합니다.
255바이트를 초과하면서, 길이를 저장하는 메타데이터 공간 자체가 1바이트에서 2바이트로 확장되어야 하거든요.
이 경우 더 이상 내부 메타데이터만 살짝 수정하는 방식(INPLACE)을 사용할 수 없게 돼요.
결국 ALGORITHM=COPY를 사용하여 테이블 전체를 재구성하고 데이터를 새로 복사해야 합니다.
이 과정에서 테이블에 공유 락(Shared Lock)이 걸리기 때문에, 서비스 운영 중이라면 치명적인 장애나 성능 저하로 이어질 수 있어요.
따라서 향후 데이터 확장이 예상된다면, 처음 테이블을 설계할 때부터 이 길이 정보 오버헤드의 임계점(255바이트)을 꼼꼼히 계산해 두는 전략이 꼭 필요합니다.
대용량 텍스트 데이터의 저장: TEXT 타입과 Off-Page

아주 긴 게시글이나 길이를 예측하기 힘든 텍스트 데이터에는 주로 TEXT 타입을 고려하게 되죠.
TEXT는 최대 길이를 명시하지 않는 대신, 내부적으로 데이터를 저장하는 아키텍처 자체가 완전히 달라요.
TEXT 데이터는 기본적으로 테이블의 데이터 페이지(B-Tree 노드) 외부에 저장돼요. 이를 Off-Page 방식이라고 부릅니다.
테이블의 실제 레코드 내부에는 데이터가 저장된 외부 공간의 위치를 가리키는 20바이트 크기의 '포인터'만 남겨두죠.
그렇기 때문에 TEXT 컬럼을 SELECT로 조회할 때마다, 이 포인터를 따라 외부 페이지를 한 번 더 참조해야 하는 추가적인 디스크 읽기 비용(I/O)을 감수해야 해요.
결론적으로 '데이터가 길어질 것 같다'는 막연한 이유로 TEXT를 무작정 선택하는 건 권장하지 않아요.
레코드의 전체 크기가 MySQL의 단일 행 최대 크기인 65,535바이트를 넘지 않는다면, 조회 오버헤드가 적은 VARCHAR를 우선적으로 검토해 보세요.
정말 제한 없이 길어질 수 있는 대용량 데이터에만 TEXT를 제한적으로 활용하는 것이 성능 확보에 훨씬 유리하답니다.
데이터베이스 설계에 은탄환은 없어요
결국 데이터베이스 설계에 "무조건 이 타입이 정답이다"라는 은탄환(Silver Bullet)은 없어요.
CHAR, VARCHAR, TEXT는 디스크 공간 확보와 처리 성능 사이에서 저마다 뚜렷한 트레이드오프(Trade-off)를 가지고 있기 때문이죠.
문자열 타입을 선택해야 할 때, 다음 세 가지 핵심 기준을 요약해 드릴게요.
- 데이터 길이가 고정적이고 업데이트가 빈번할 때 ➡️
CHAR- 주저 없이
CHAR를 선택해 주세요. 상태 코드, Y/N 플래그, 해시된 비밀번호 등은 고정 공간을 미리 확보해 두어야 로우 마이그레이션으로 인한 성능 저하를 든든하게 방어할 수 있어요.
- 주저 없이
- 데이터 길이가 가변적이고 조회가 주를 이룰 때 ➡️
VARCHAR- 공간 효율성이 뛰어난
VARCHAR가 최선의 선택이에요. 단, 미래에 스키마를 변경(Online DDL)할 때 락(Lock) 이슈가 발생하지 않도록 초기 최대 길이를 신중하게 설계해야 한답니다.
- 공간 효율성이 뛰어난
- 길이를 예측할 수 없는 대용량 텍스트일 때 ➡️
TEXTTEXT타입을 활용하되, Off-Page 저장 방식으로 인해 추가적인 디스크 읽기 비용(I/O)이 발생한다는 점을 꼭 인지하고 쿼리를 최적화해 주세요.
가장 훌륭한 테이블 설계는 결국 '우리 서비스의 데이터가 어떻게 생성되고, 얼마나 자주 변경되며, 어떻게 소비되는지' 그 생애 주기(Lifecycle)를 정확히 이해하는 것에서 출발해요.
이 글이 다음 프로젝트에서 견고하고 효율적인 데이터베이스를 설계하는 데 명확한 기준이 되었기를 바랍니다!
'Computer Science > Data 📊' 카테고리의 다른 글
| 데이터베이스 트랜잭션 완전 가이드 - 개념부터 ACID, MySQL, 격리 수준, 스프링 적용까지 (0) | 2024.05.16 |
|---|---|
| 데이터베이스 vs 데이터 웨어하우스 vs 데이터 레이크 (0) | 2024.03.08 |
| Docker 환경에서 PostgreSQL Master–Slave Replication 구축하기 (0) | 2024.02.07 |
안녕하세요, 저는 주니어 개발자 박석희 입니다. 언제든 하단 연락처로 연락주세요 😆


